
머신러닝 Good bye 하고 딥러닝 Welcome 하고 싶습니다

3차 미니프로젝트가 끝이 나고 , 말로만 들었던 그 딥러닝이 돌아왔습니다. 굉장히 말로만 많이 들었었지, 두려움이 많았습니다. 하지만 에이블 스쿨의 강사님께서 굉장히 직접 손으로 그리면서 친절히 알려주셨기에 생각만큼 두렵지는 않았습니다.
핵심 point
| 1. 딥러닝은 머신러닝과 달리 가중치를 스스로 업데이트하며,오차를 줄이며,스스로 최적의 가중치를 찾아냄 |
| 2.회귀와 분류에따른 모델링의 사용기법을 잘아야 합니다. 특히 과적합을 방지하기 위한 방법알기 |
| 3. 머신러닝처럼 딥러닝 코드구조와 순서는 필수로 암기! |
딥러닝을 배우기전 강사님께서 머신러닝과의 차이를 중요하게 설명해 주셨다
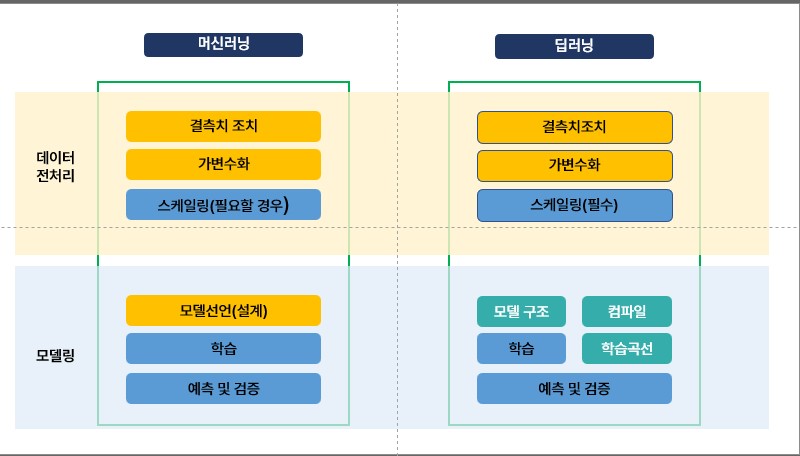
가장 큰 차이는 모델링 과정에서 모델구조와 컴파일(model.complie) 구문이 추가되는 것이다.
컴파일을 하는 이유는 컴파일을 통해 어떻게 오차를 줄이고 가중치를 업데이트할 것인지에 대한 조정이 필요하기 때문!
또한 스케일링 또한 필수이다!
딥러닝을 배우면서 제일 중요하다고 생각한 것
1. 회귀모델과 분류모델의 딥러닝 적용 시 각각의 loss_function(손실함수), optimizer, dens별로 달라지는 코드를 숙지
2. 입력층과 은닉층 출력층을 어떻게 형성해야 할지 손으로 직접 그려보며 어떻게 작용하는지 생각하기
3. 파라미터를 조정하기 위해 머신러닝 그리드서치가 아니라,. history 메서드를 통해 학습곡선을 보며 epoch, batch, dense층을 조조정해 야함
나중에 내가 보기에도 다른 분이 보기에도 유용하도록! 주요 개념을 정리해 두었다
주요 개념 정리
- 회귀모델링 - 분류모델링-성능관리
| 구분 | 회귀 모델링 | 분류 모델링 | 성능 관리 |
| 기본 개념 | - 연속적인 값을 예측하는 문제로, 결과가 특정 범위의 실수 값으로 표현됨. - 입력과 출력 간의 관계를 학습하여 새로운 데이터의 결과를 예측. |
- 사전 정의된 클래스(범주)를 예측하는 문제. - 이진 분류(Binary)와 다중 분류(Multi-class)로 나뉨. |
- 모델의 학습 성능을 정량적으로 평가하고, 데이터 및 모델의 품질을 유지 및 개선하는 작업. |
| 목적 | - 연속형 값 예측 (예: 가격, 온도) | - 클래스 예측 (예: 고양이 vs 개) | - 모델의 일반화 성능 및 안정적인 학습 과정 유지 |
| 손실 함수 | - Mean Squared Error (MSE): 예측값과 실제값의 차이를 제곱한 후 평균 계산. - Mean Absolute Error (MAE): 절대 차이값의 평균 계산. |
- Binary Cross-Entropy: 이진 분류의 로그 손실 계산. - Categorical Cross-Entropy: 다중 분류에서 확률 간의 로그 손실 계산. |
선택된 손실 함수가 문제와 데이터에 적합한지 확인 |
| 평가 지표 | - Mean Absolute Error (MAE) - R-squared (결정 계수) |
- Accuracy, Precision, Recall, F1-Score, AUC-ROC | 데이터셋을 나눠 검증 및 테스트, 과적합 방지 |
| 출력층 활성화 함수 | 없음 (Linear): 회귀의 결과는 연속적인 실수 값. 활성화 함수 없이 바로 출력. |
Softmax: 다중 분류에서 클래스 확률 예측. Sigmoid: 이진 분류에서 클래스 확률 예측 |
출력층 활성화 함수가 예측값 범위에 맞는지 확인 |
| 데이터 준비 | - 정규화 (Normalization): 데이터를 [0,1] 범위로 변환. - 표준화 (Standardization): 평균이 0, 분산이 1이 되도록 변환. |
- One-Hot Encoding: 다중 분류의 범주형 데이터를 이진 벡터로 변환. - Label Encoding: 범주형 데이터를 숫자로 변환. |
데이터 누락 여부 확인, 이상값 제거 |
| Optimizer | -Adam | Adam | 학습 속도 및 수렴 여부 점 |
| 학습 과정 | - Learning Rate Scheduling: 학습률을 점진적으로 감소시켜 안정적인 수렴 유도. - Epoch 수 결정: 과적합 방지를 위해 적절한 반복 횟수 선택. |
- Early Stopping: 학습 중 과적합 발생을 감지하고 조기에 종료. - Epoch 수 결정: 모델 학습 중 성능 변화를 지속적으로 모니터링. |
학습률 감소 스케줄 사용, 과적합을 방지하기 위해 적절한 조기 종료 기법 적용 |
| 활용 프레임워크 | - TensorFlow, PyTorch, Keras | - TensorFlow, PyTorch, Keras | Scikit-learn, TensorBoard 등을 활용해 실험 관리 및 모델 평가 |
하이퍼 파라미터 튜닝과 과적합 방법
| 개념 | 회귀모델링 | 분류모델링 | 성능관리 |
| 하이퍼파라미터튜닝 | - Batch Size: 한 번에 학습할 데이터의 크기. - Learning Rate: 학습 속도를 제어하는 값. |
- Batch Size: 한 번에 학습할 데이터의 크기. - Learning Rate: 학습 속도를 제어하는 값. |
Hyperparameter tuning: Grid Search, Random Search, Bayesian Optimization |
| Overfitting 방지 | - Dropout: 일부 뉴런을 무작위로 제거하여 과적합 방지. - Regularization: L1/L2 규제 사용 |
- Dropout: 일부 뉴런을 무작위로 제거하여 과적합 방지. - Regularization: L1/L2 규제 사용. |
L1/L2 Regularization, 데이터 증강(Data Augmentation) |
| 결과 시각화 | - 실제값 vs 예측값의 Scatter Plot | - Confusion Matrix: 모델의 예측 성능 확인. - ROC Curve: 클래스 구분 성능 시각화. -Classification_Report : 전체 요약적으로 확 |
학습 곡선(Loss/Accuracy vs Epochs) 그래프 활용 |
| 고려사항 | - 잔차 분석 (Residual Analysis): 예측값과 실제값의 차이 분석. | - 클래스 불균형 처리 (Oversampling, Undersampling, SMOTE). | 모델 배포 및 성능 지속 모니터링 (Drift 감지, 데이터 재학습 필요성 평가). |
개념양이 너무 많아서 이해하기도 어려웠지만, 요지는 기초코드를 암기한 채로 각 요소들이 왜 변경되는지 이해하면 상대적으로 어렵지 않게 이해가 가능하다! 이번에 EPOCH라는 것을 지정하면서 횟수가 늘어날 경우, 연산시간이 오래 걸린다
이에 에이블스쿨에서 제공한 구글코랩을 처음 사용해 보았습니다. 굉장히 유용했고, 머신러닝과 달리 학습곡선만 보면서 할 수 있는 점이 좋았습니다. 결론은 익숙지 않으니 천천히라도 계속 반복해야겠습니다. 이 글을 보는 분들도 딥러닝이 어렵다면, 강의 외에도 기타 다른 자료들을 참고하여 꼭 스스로 내 걸로 만드는 시간을 확보하시면 유용합니다 :)
느낀 점
1. 공부를 하면서 기본적인 코드는 암기를 하고 있는 것이 중요하다
2. 진작에 외울걸 그랬다. 이해도 물론 해야 하지만, 선 암기 후이 해가 적절한 걸 알게 되었다
3. 아직 초짜배기인데 그래도 어차피 처음 배우는 건데 스펀지처럼 최대한 흡수해야지!
난 할 수 있는 ABLER이다! 아자아자!
'KT에이블스쿨' 카테고리의 다른 글
| [KT 에이블스쿨 6기]DX트랙 11주차 후기 (1) | 2024.11.26 |
|---|---|
| [KT 에이블스쿨 6기]DX트랙 10주차 후기 (0) | 2024.11.26 |
| [KT 에이블스쿨 6기]DX트랙 8주차 후기(3차 미니 프로젝트 포함) (0) | 2024.11.26 |
| [KT 에이블스쿨 6기]DX트랙 7주차 후기 (0) | 2024.10.29 |
| [KT 에이블스쿨 6기]DX트랙 6주차 후기 (0) | 2024.10.29 |